Batch Runner
Sliderule's Batch Runner is a great way to run many executions at a time, to test out your workflows or for making large numbers of decisions in asynchronous "batches".
Through the Batch Runner tab in Sliderule, you can create a Job to run a batch of inputs through a workflow. You can use CSVs or SQL queries where the column headers match the expected Input fields for your workflow. Each row will then be used as the input for an execution.
Note: the Batch Runner is designed to run in the background, so jobs won't affect the performance of your live workflows. This means they won't run as quickly as the production versions of your workflows, and shouldn't be used for high speed situations.
Using a CSV as Input
You can upload a CSV like the example below, where column headers match the expected input fields for your workflow. Each row will then be used as the input for an execution.
| user_id | amount | ip_address |
|---|---|---|
| 1 | 300 | 11.111.1111 |
| 2 | 400 | 11.111.1111 |
| 3 | 750 | 11.111.1111 |
The job would execute your workflow 3 times, and the result would be an updated csv including the output from the specified workflow and version.
From the Batch Runner tab in Sliderule, click Create to start a new job, and select Create with CSV. Then, specify a Workflow and Version. Finally, upload your CSV of inputs here, and check if there are any warnings for missing columns. When you're ready, kick off your new job.
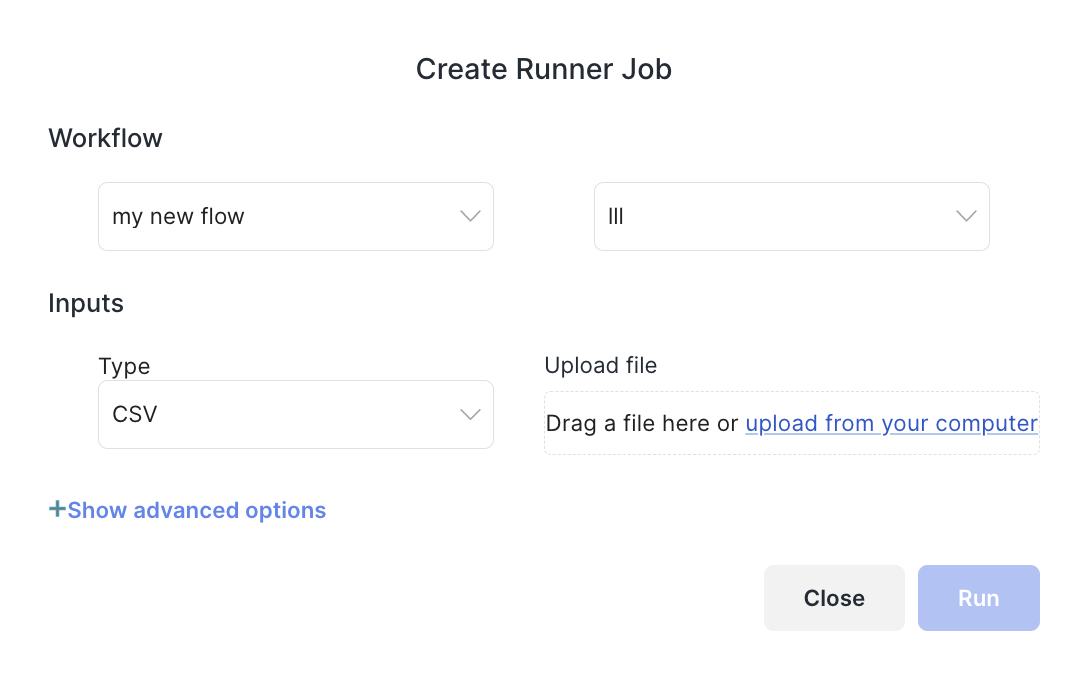
Once a job is added to the queue, you'll see it listing as Pending or Running in the table. When the Status changes to Done, you'll see a download link to download your results spreadsheet.
Using a SQL Query as Input
You can also Create a new job using a SQL query. Click Create to add a new job, then select SQL Query from the option menu. Pick a workflow and version you'd like to run.
Next, select a Credential for the Database you'd like to use in your query. If you don't see the Database Credential you want listed, you'll need to add a database credential
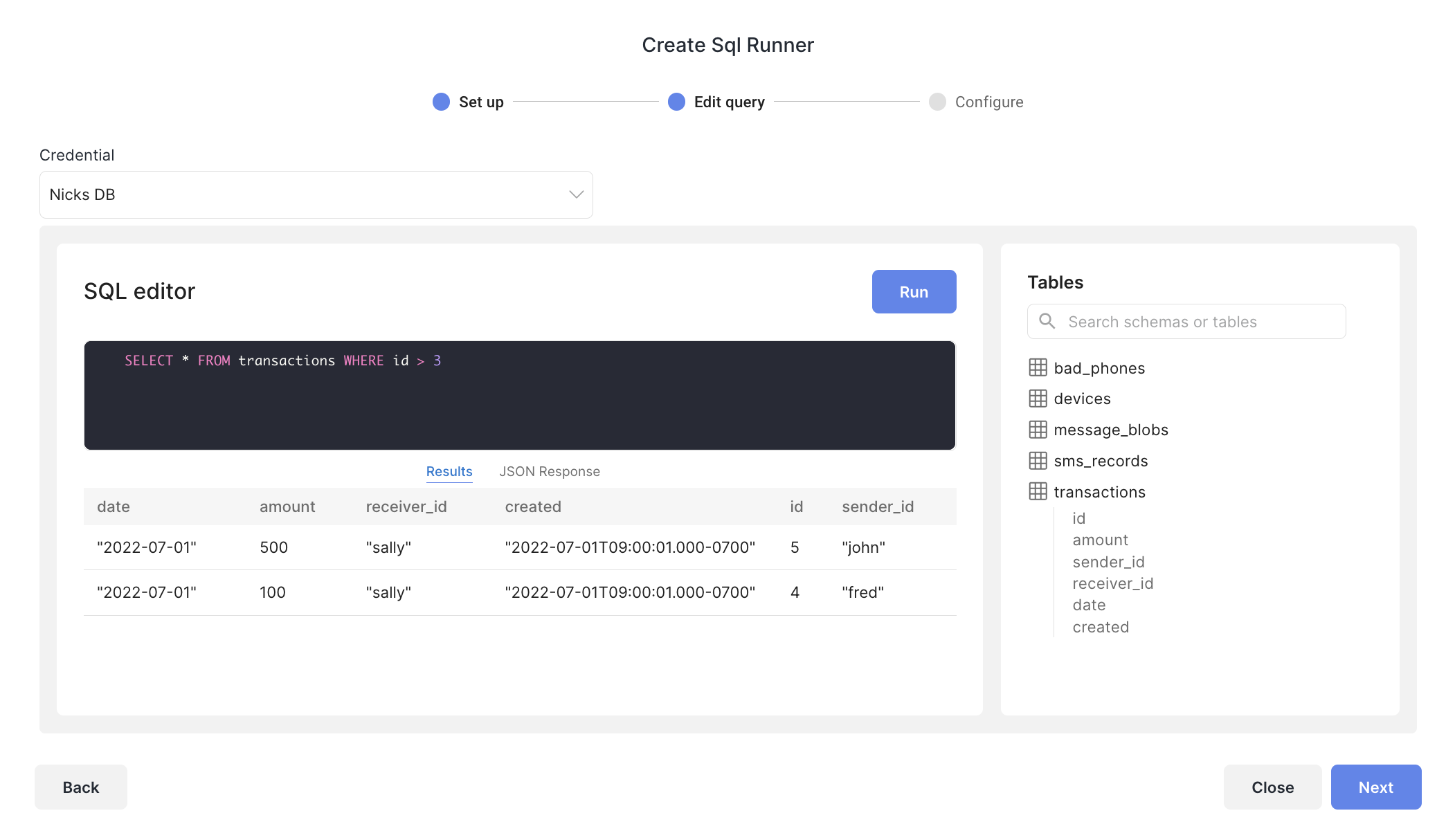
Once you've selected a credential, you'll see the available tables and columns appear on the right hand helper panel. Write your query and select Fetch Sample Row.
Each column returned will be used as an Input field in your workflow, and each Row will be run as an execution. You can select One Time or Recurring for your job, then click Run to create your Job. When the Status for your job changes to Done, you'll see a download link to download your results spreadsheet.
Scheduling Recurring Jobs
Recurring jobs are currently only available for SQL Query jobs. Select Recurring on the final step of the Job Creation. You can then pick a start time for the first run, as well as recurrence frequency option in minutes, hours, or days.
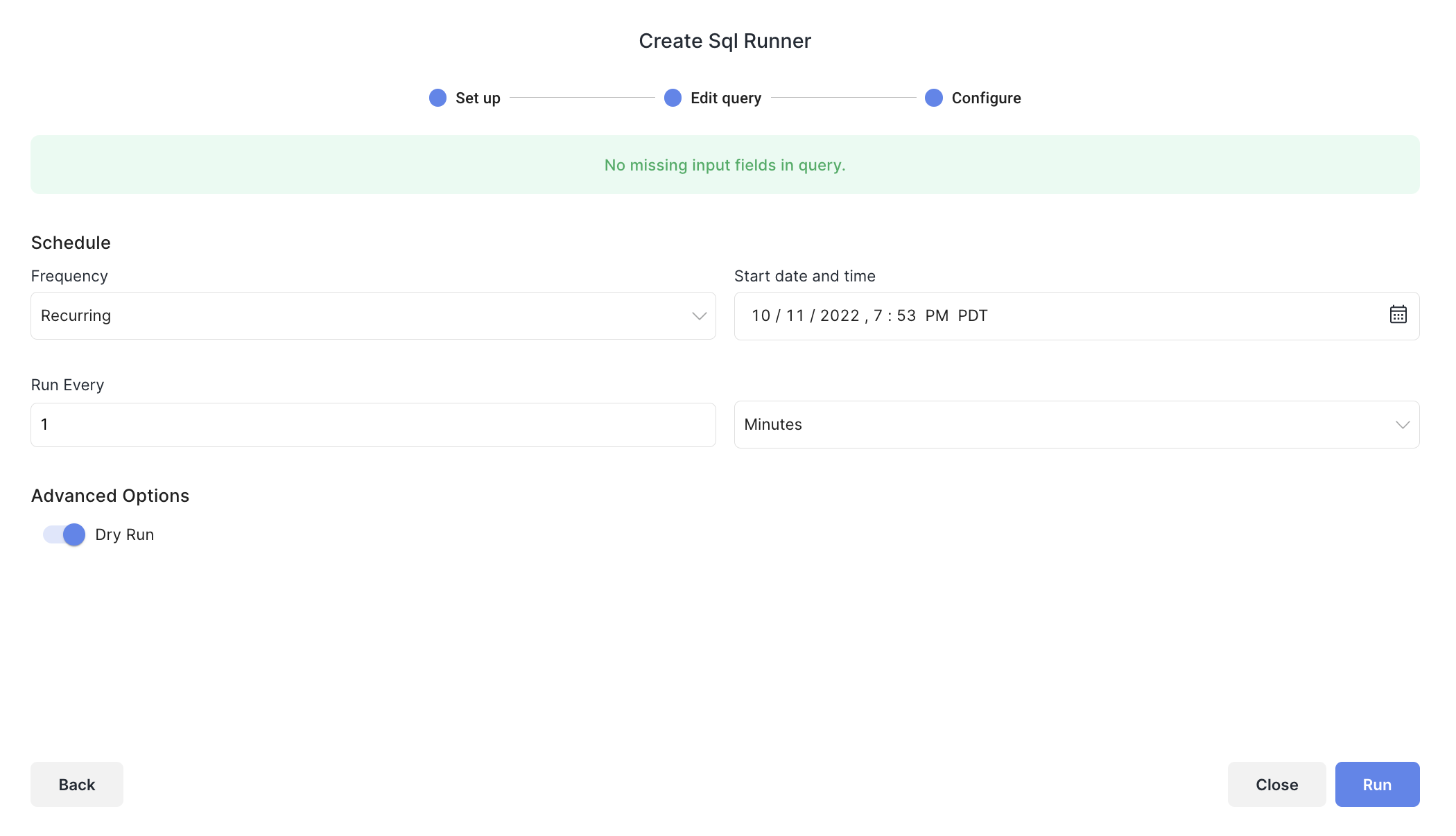
Once you click save, you can click on the Recurring Jobs tab in the Batch Runner to view your jobs, edit them, or deactivate them. Each time your Recurring Job runs, it will add a record to the Job History table as well.
Running Batches via API
Beta Feature
Document and Job APIs are both in Beta. Contact your Support team if you run into any issues
You can also create batch jobs using our APIs. This process requires 4 API calls:
-
Documents API to upload a CSV
- POST request to /v1/document
- Set Content-Type to application/octet-stream, and include your CSV in the Body
- Documents API will return a documentId for the uploaded CSV file
-
Jobs API to create a new job
- POST request to /api/user_job
- Include the documentId from Step 1, as well as configuration for the job
-
Jobs API to check status (optional)
- GET request to /v1/runner_job/{id} using the
idreturning in step 2
- GET request to /v1/runner_job/{id} using the
-
Documents API to download results from finished job (optional)
- Once calls from step 3 return a
STATUSof "done", then grab the outputDocumentId - GET request to /v1/document/{id}/download to retrieve the output CSV
- Once calls from step 3 return a
Updated over 2 years ago